机器学习入门
1、学习资源获取渠道 2、机器学习第一语言Python 3、机器学习算法基础 4、深度学习框架基础
下面说,在机器学习这一领域,需要掌握哪些基本的Python知识。
一、Python的基本语法和应用
1、基本元素
基本上就是整数、浮点数、字符串、变量、布尔值、list、tuple、dict和常用格式文件等元素的操作和使用。
2、判断和循环
你可以理解为把上面说的一些基本元素通过if..else...., for和while等来做一些判断和循环。判断很简单,在某个节点上,如果是A,下面一步应该怎么走,如果是B,下面应该怎么走。循环也不难理解,比如说我们有一个list[1,2,3],我们把里面的每个元素都取出来做某些处理。
3、函数和类
你可以理解为我们故意把某些逻辑做成类或函数,在某些需要用到这端逻辑的场景下,我们可以直接调用相关函数,而不用重新去写这段逻辑的代码,其实就是程序猿常说的不要重复造轮子的事情。
聪明的你是不是感觉有点熟悉似曾相识啊,对的哇,前面说的库里的模块,其实就是一个个封装好的函数哈。
再次强调,这只是你需要掌握的最最基本的东西,Python的世界可是大着呢!
二、科学计算库numpy和pandas
numpy和pandas是非常出名两个科学计算库,很多做数据分析和金融的童鞋都会用到。
那为什么机器学习会用到这两个库了?
我们先来无脑吟唱下这句话:在机器的世界里,万物皆可为向量。向量其实也算是一维的矩阵,我们的训练数据和要预测的数据也都是以矩阵的形式喂给机器的。
而numpy和pandas可以说是处理矩阵的好手,所以通常会用numpy和pandas对数据进行处理后再喂给机器,就我目前的实践经验来说,numpy应用的场景会比pandas多些。
其实好一些机器学习框架(如TensorFlow和Mxnet)也有自己处理数据的模块,但大多是通过封装numpy得到的,使用的方法也很像,所以无脑去上手numpy肯定不亏。
关于numpy和panda,我给大家提供一个PPT《机器学习numpy与pandas基础》,大概100来页,两个库的基本知识都说到了,感觉还�不错,已经放在云盘里了。
另外,网上有一篇叫《十分钟搞定pandas》的文章梳理得还算清晰到位,大家不妨也去读读,反正也花不了多少时间。
《机器学习numpy与pandas基础》获取方式:详见文末
《十分钟搞定pandas》阅读地址:http://t.cn/RpYFh6h
三、画图库matplotlib
在搞机器学习过程中,画图不是必须的,但通过画图能够让我们可视化一些数据,从而能够更直观地观察数据特征和训练过程。
我们可以把每一个数据样本都理解为其特征空间中的一个点。当我们把这些数据样本在其特征空间中画出来后,就可以了解到数据的分布了。
通过观察数据分布是可以发现一些规律的,比如下图的是机器学习中著名的手写识别体数据集mnist(手写的0到9十个数字的图片)的数据经过处理后的可视化效果。
是不是有发现相同数字的数据都分布得比较近?其实不难理解,两个数据样本在特征空间中的距离越近,就说明它们越像。
我们不妨再微微展开一下,话说我的好友王建国童鞋是个二次元妹纸颜控,在他眼中每一个二次元妹纸都可以被量化为四个维度的数据样本:脸萌的程度(0-100)、声音萌的程度(0-100)、胸大的程度(0-100)、腿长的程度(0-100),所以每个二次元妹纸都是以上四个维度构成特征空间中的一个点。
聪明的你知道三维以内的空间是可以画出来的,那如果一个模型里的数据超过三维,那我们是不是就不能可视化了?
好问题,数据超过三�维后的确是不能够可视化,因为我们根本就画不出来的嘛。
但你可能还记得我们之前说过有一类机器学习算法,是可以在保证数据信息损失尽可能小的前提下压缩数据维度的,所以我们可以通过这类算法先把数据压到三维以内,再做可视化处理。
有点抽象?那李杰克说具体点,我们把王建国童鞋认识的所有二次元妹子的数据样本都喂给机器,机器扑哧扑哧研究后,发现脸比较萌的妹纸通常声音也比较萌,然后就搞出一个新的维度来代替了脸萌程度和声音萌程度两个维度。所以我们这些二次元妹纸的数据就被压成了三个维度的数据,这个时候我们就可以通过可视化来看数据分布了。
另外,我们还可以通过matplotlib来画出训练过程中一些数据的变化,比如下图这个最简单的线性回归训练拟合的过程:
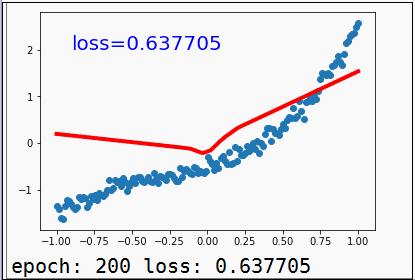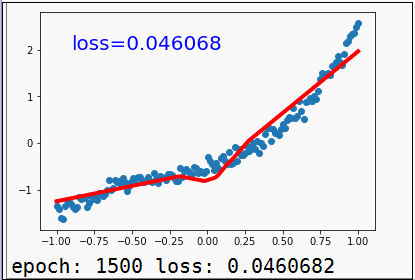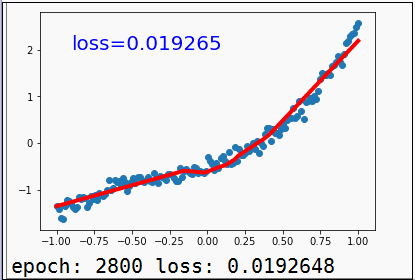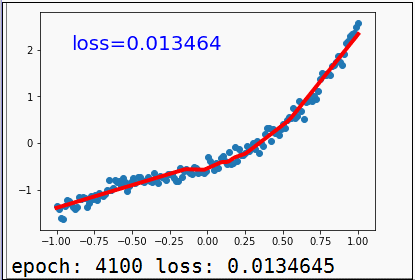
matplotlib的基本操作学习成本并不高,基本一到两天,可以把里面基础常用函数模块搞得差不多懂,建议可以学学。下面这篇文章《matplotlib绘图可视化知识点整理》,是李杰克觉得基本知识点梳理得还不错的的,各位同学可做参考。
《matplotlib绘图可视化知识点整理》阅读地址:http://t.cn/RqDxDo8
四、一些Python学习的建议
《笨办法学Python》获取方式:详见文末。李杰克也提供了PDF电子版给大家,同样放在了云盘中。
《廖雪峰Python教程》阅读地址:http://t.cn/RK0qGu7
《Python100例》阅读地址:http://t.cn/RfOJSc5
这些文章满足我们需求:
1、只用最简单的两三个库;
2、手牵手一步一步地教学,想不学会都难的那种;
如果你已经具备了Python基础,按着我分享出来的资料折腾的话,李杰克保证你两三天可以折腾出一个爬虫
《从零开始写Python爬虫》
《 1.1 requests库的安装与使用》阅读地址:http://t.cn/RTuUuf7
《1.2 BS4库的安装与使用》阅读地址:http://t.cn/RTu4PLz
《1.5 爬虫实践: 获取百度贴吧内容》阅读地址:http://t.cn/RTu4ZbV
《1.7 爬虫实践: 排行榜小说批量下载》阅读地址:http://t.cn/RTu4UHw
《1.8 爬虫实践: 电影排行榜和图片批量下载》阅读地址:http://t.cn/RTu45gz
3、机器学习数学基础
一、高等数学
1、导数及偏导数,对应机器学习中的梯度,机器学习中学习的参数需要通过梯度下降进行更新;
2、复合函数的链式法则,同1一样,目的也是为了求出梯度更新参数,但因为深度学习网络有多层,所以模型的预测函数是个复合函数,我们需要通过链式法则从后往前求出每层参数的梯度,进而更新每层里的参数,这也就是大名鼎鼎的“反向传播法”;
3、同时可以去了解下数学中的最优化问题,大概就是目标函数在什么条件下能够取到最值的问题,因为机器学习的问题到最后都是要转化为一个损失函数最优化的问题。
二、线性代数
1、标量、向量、矩阵及张量的定义及运算,让我们再回顾下,在机器的眼里,万世间物即可为矩阵,机器学习的过程其实也就是矩阵计算的过程。这也就是NVIDIA的GPU在近两年那么火的原因,因为GPU在矩阵计算上天然有很大的优势。
2、范数,对应机器学习中正则项,正则项通常会加在已有的损失函数上用来减少训练的过拟合问题;
3、常见的距离计算方式:欧式距离、曼哈顿距离、余弦距离等,我们之前说过数据样本可以表示为其特征空间里的点,而距离可以用来衡量他们的相似度。
三、概率论
1、条件概率、贝叶斯,基于概率论的分类方法经常会用到;
2、期望与方差,机器学习里一般都会对数据进行normalized的处理,这个时候很可能会用到期望和��方差;
3、协方差,能够表征两个变量的相关性,在PCA降维算法中有用到,变量越相关,我们越可能对他们进行降维处理;
4、常见分布:0-1分布、二项分布、高斯分布等,高斯分布很重要,数据normalized跟它有关,参数的初始化特跟它有关;
5、最大似然估计,在推导逻辑回归的损失函数时会用到。
四、信息论
这块东西其实应该不属于数据知识,没有太多东西就姑且也放到一块吧。你暂时只需要去了解下交叉熵的概念即可,大概知道这东西跟分类问题的损失函数有关即可哈。
李杰克温馨提示:
大家一开始能把这些知识点搞懂是最好,没搞懂也不要慌,因为贴心的我给大家推荐的机器学习资源里都会通常都会用通俗浅显的方式去做相关推导,即使你没有搞懂这部分数学知识也不会特别懵逼,当然,用心准备总是最好哒!
4、机器学习算法基础
李杰克给大家推荐的第一个学习资源是台湾李宏毅老师的《一天搞懂深度学习心得》。
《一天搞懂深度学习心得》观看地址:http://t.cn/RTukvY6
关于机器学习的英文资料比较多,国语的除了台湾的李宏毅、林轩田老师的课程外就是一票辅导机构在那里折腾了
李杰克给大家推荐的第二个学习资源是共计20集的视频教程《DeepLearning.TV》。
《DeepLearning.TV》视频观看地址:http://t.cn/RTuDdSQ
《DeepLearning.TV》虽然有20集的长度,但每集只有3到4分钟。
两套视频刷完后,李杰克还给你准备了一份300页PPT的大礼包——李宏毅老师的《深度学习介绍-李宏毅》,这算是我见过最全面最清晰的PPT,你可以花上一些时间自己去啃一遍。
《深度学习介绍-李宏毅》PPT下载地址:详见文末
接下来我们终于要开始接触Ng的《Machine Learning》了。其实在很多机器学习大拿眼中,Ng最大成就不是在学术上,而是作为AI布道者让更多人知道了机器学习,他也是目前和工业界互动得最好的AI科学家,最近不是又刚成立了个landing.ai要推动企业转型么?
《Machine Learning》视频观看地址:http://t.cn/RYpskDe
大家需要注意的一点是,《Machine Learning》讲的更多的还是传统机器学习,深度学习知识作为其中很小的部分一带而过,有多么少,李杰克没记错的话大概也就是100多章节里花了两三个章节说讲了下神经网络吧。
你要是问李杰克资次不资次你通过《Machine Learning》学习传统机器学习的算法,我当然是资次的,Ng讲课讲得确实是一流,听课体验很棒!
李杰克的建议是,大家可以通过《Machine Learning》去学习机器学习中的基础知识,我拎些重要的出来:损失函数、梯度下降、线性回归、逻辑回归、SVM、反向传播法、正则化、KNN、K-Means、PCA,大家可以优先重点搞懂这些东西,你进入到深度的知�识储备算是基本够了。
当然时间充裕的情况下李杰克建议大家把所有章节都好好学习下,《Machine Learning》绝对是你可以看上几遍的课程,李杰克也打算等稍微没那么忙了再去重温一遍呢。
另外,《Machine Learning》是通过一个类似Matlab的软件Octave来教学,时间有限的情况下可以考虑不学,因为到目前为止李杰克就没有在第二个地方见到过这个软件的使用,大家学了估计也很难用上.......
《Machine Learning》有两版,一版是斯坦福教室里录制的版本,一版是Ng后来录制的版本,李杰克这里给大家推荐的是后者,相信我,前者直接上手真的可能会看哭的,别问我怎么知道......
如果非常简要地把深度学习概括为两个方向,那就是图像处理和语音处理,看过我前一篇文章的童鞋会知道两者分别主要对应的是卷积神经网络和递归神经网络的应用。
李杰克虽然也对递归神经网络有过接触,自己也通过递归神经网络写过一个能够写古诗的AI,但确实没有系统学习过什么资源,本着no experience no bb的原则,递归神经网络方面的资源暂不做推荐。
说到图像处理领域,有些童鞋可能已经听闻过李飞飞的大名,妥妥的计算机视觉领域的大牛,接下来给大家推荐的学习资源也就是由李飞飞和她的两位博士生Justin和Serena教授的《Stanford CS231N 2017》。
额......话说李飞飞在第一节课出现了一会后就人间蒸发了,但并不影响我们安静地坐下来欣赏Serena小姐姐的美颜。
讲真,第一次听这个华裔的小姐姐说话的时候,李杰克还是被惊艳到了,她说话的感觉简直就是Ivanka大公主的翻版。
《Stanford CS231N 2017》观看地址:http://t.cn/RTueAct
那个啥,我猜你肯定是点开了图,并且还放大了来看......
当然,有些童鞋可能会说,李杰克你推荐的都是些英语视频,我的英语水平去看这些视频可能会有些吃力怎么办?
这当然不是问题啦!别忘了李杰克可是做过产品经理的哇,怎么可能考虑不到这种需求呢?对于英语一脸懵逼,不要慌,李杰克仍然有不错的资源推荐给你——李宏毅老师的《机器学习》和《深度学习》。
《李宏毅机器学习2017》观看地址:http://t.cn/RpO3VJC
《李宏毅深度学习2017》观看地址:http://t.cn/RpO3VJK
如果你英语能力还能支撑你看英文视频的话,李杰克当然建议你优先看推荐的英文资源!
有童鞋也许会问,李杰克你给我们推荐的都是视频,有没有什么书要推荐哇?
讲真,网上推荐的那些大家都认为是经典的书李杰克基本都买了纸质版,但其实并没有看掉多少。李杰克还是跟大家说一下自己或多或少读过的一些书,毕竟也都是些被别人列为经典的书,仅供参考。
首先要说的是周志华的《机器学习》,江湖人称西瓜书,因为它的封面是个大西瓜.....周志华算是国内机器学习的权威了,李杰克粗粗看了一两个章节后就果断弃坑,选择了Ng的视频来学习入门,因为我感觉自己看这部书效率并没有看Ng的《Machine Learning》高。
李杰克还看过Peter Harrington的《机器学习实战》,其核心是教你用python来实现机器学习中的算法,我看了一半多一些的时候也弃坑了,一方面是自己渐渐明确自己的兴趣所在是深度学习,另一方面是我接触到了Tensorflow等深度学习框架,
李杰克目前还在看的是Ian Goodfellow等一票人合著的《Deep Learning》,Ian Goodfellow�就是那个搞出了对抗式生成网络(类似于左右手互搏术的东西)的家伙,大概率李杰克不会弃坑,毕竟这也是本被称之为深度学习圣经的书。
我的建议是入门阶段可以不用购买书籍,除非你跟我一样颈椎不大好需要买个七八本书来垫垫电脑......
说正经的,不用买书是因为我把这些被大家被奉为机器学习经典的书籍(PDF版,包含上述三本)都打包放在了云盘里,大家直接去下载就好了。
毕竟大家出门在外养家糊口都不容易,能省一点算一点了,而且万一你的颈椎比较争气一直都还比较好那你买的书不就一直派不上用场了么对不对?
最后,无比贴心的李杰克还给大家准备了两个可以辅助大家学习和理解deep learning的工具。对你来说绝对是有用还好玩的东东,一般人我还不告诉他的呢(傲娇脸)!
一个是TensorFlow出的网页工具playground,其实就是游乐场,我们可以去玩一玩,相信对大家学习深度学习一定会有些帮助的。
playground提供了几种简单类型的data,你可以去调节网络结构、学习率、激活函数、正则项等参数,你可以非常直观地看到每个神经元和相关输出的变化,体会到简化的深度学习模型调参的过程。
下面这个其实是张动图,来,用心感受下......

tensorflow playground使用网址:http://t.cn/RqJTH47
另一个工具是ConvNetJS,它把一些经典数据集(如Mnist和Cifar-10)每层网络的输出可视化出来,对你去理解不同网络做了什么事情有大大的帮助滴!
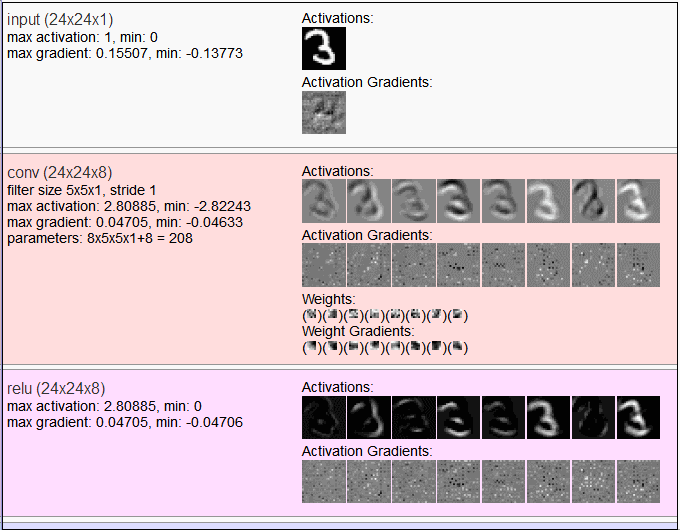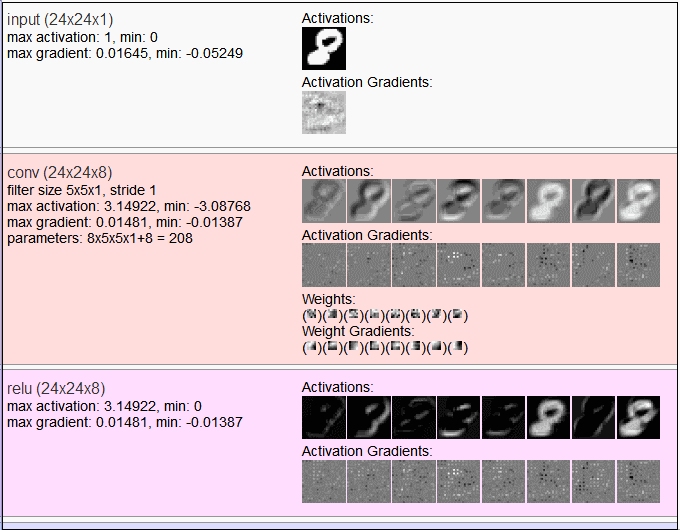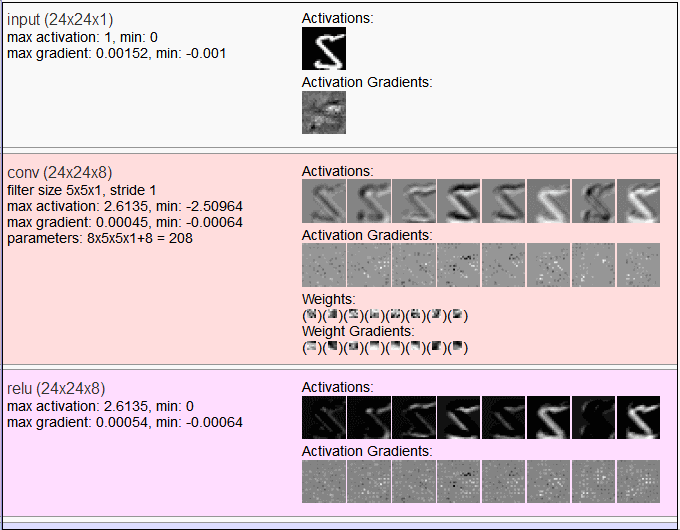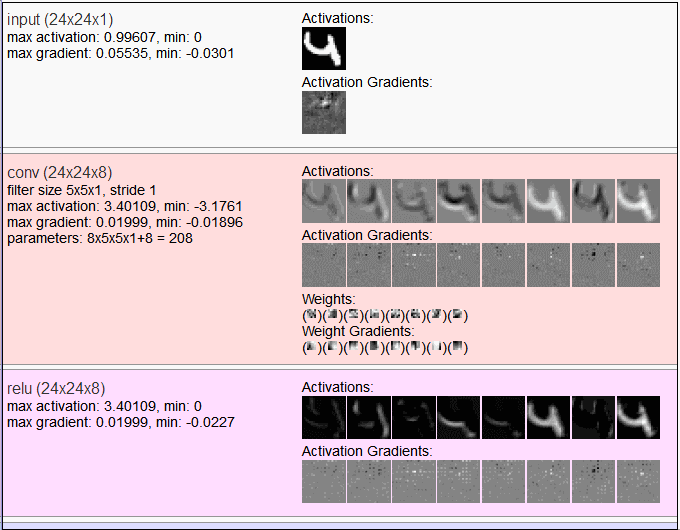
ConvNetJS使用网址:http://t.cn/8kFEqvU
5、深度学习框架基础
我的天啦,你居然还在看?旁友,你不用工作的么?你们公司还差不差人啊,会打dota玩农药的那种?
不开玩笑,讲真,我知道你一路看起来不容易,毕竟李杰克也是花了两个礼拜工作之余的时间写的,还是水分比较少容易消化不良的那种.....
所以,努力的你晚上一定要去吃顿好的犒劳下自己才对得起自己嘛!
什么?你晚饭吃过了?
晚饭吃过了还可以再吃顿宵夜嘛,反正不吃你也是瘦不下去的对不对。
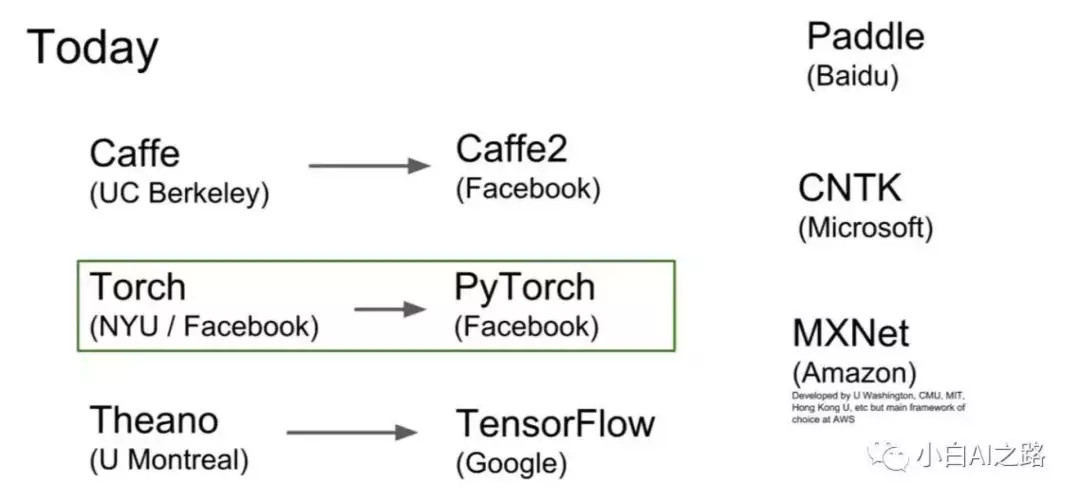
我们再次回到正题哈童鞋们(严肃脸),现在来说说机器学习框架的事情,同样的,这里我们专指深度学习框架。讲真,我写得有点累了,就放张cs231课程里的图吧,大家自己看看这些框架与大学和企业的关系。
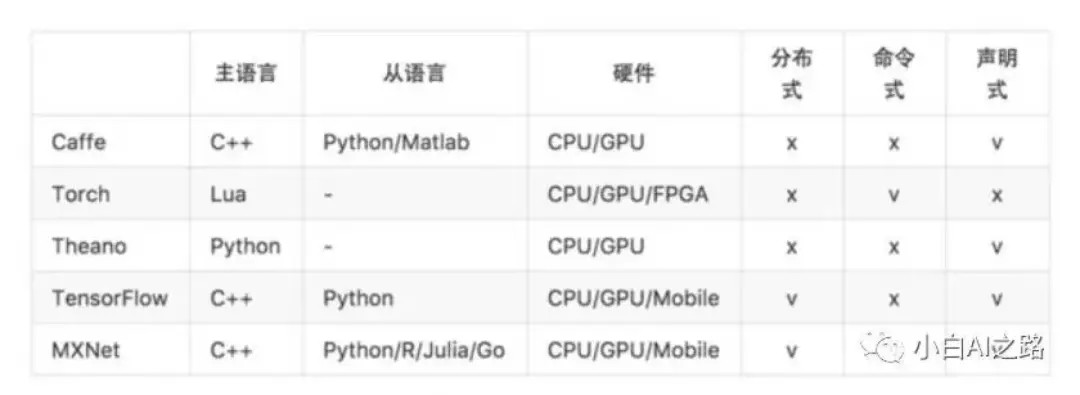
不同框架间的比较见下图,李杰克暂时也不打算展开说:
李杰克尝试过Tensorflow、Mxnet和Keras三种�框架,以使用Tensorflow为主,其他框架暂时没怎么接触。
今天重点要跟大家说的Tensorflow这个框架,Tensorflow背靠Google大树,是目前最火的框架,如果你想做一名AI工程师,那学Tensorflow一定是最好的选择,类似于一招鲜吃天下的意思。
如果你是产品经理,并不想花太多时间在框架上,但又想自己去实现一个神经网络模型的话,那李杰克建议去学习Keras。
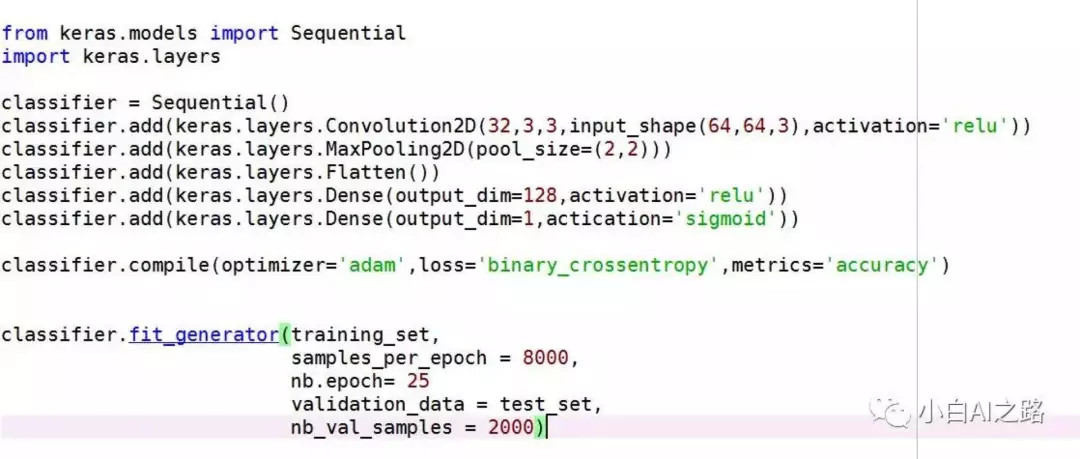
Keras基于Tensorflow又进行一层封装,当然也有基于Theano版本的,因为高度封装,使用起来异常简单,简单到什么程度呢?
你只需要十来行代码就能搞出来一个简单神经网络模型,但与此对应的是灵活度并不高,但对于产品经理一类的童鞋来说已经妥妥地够用了,再贴一下我之前写过的一个模型代码给大家看看有多简单:
关于框架的学习,李杰克同样有一些不错的视频资源推荐给大家,大家可以通过看视频入门,但之后实践过程中碰到问题更多的是需要去查看文档去解决问题哈。
对于Tensorflow,推荐大家看的第一个资源是视频《不用博士学位玩转Tensorflow深度学习》。
这个视频应该是Google云大会上的一个演讲,全程约两个小时,估计下面也坐了很多小白,所以讲得还是蛮容易接受的。
视屏中的小哥基本上是全程手把手地带你用Tensorflow分别搭建一个CNN模型(卷积神经网络)和RNN模型(递归神经网络),基本上看完你也算是有点入门了。
《不用博士学位玩转Tensorflow深度学习》观看地址:http://t.cn/RTuemTK
另外,我��的云盘里还有一份《三天速成Tensorflow PPT-香港科技大学》的PPT,讲得也是非常简明易懂,估计你花费大半天时间就可以过完了,也是一份非常好的入门资料,大家可以自行去下载学习。
《三天速成Tensorflow PPT-香港科技大学》下载地址:详见文末
网上还有一个叫莫烦的童鞋做的《Tensorflow教程》视频教程不错,每集长度也就几分钟,但相关基本深度学习的知识和Tensorflow实现都讲到了,可以说是非常棒,用来入门是妥妥的不错的!
莫烦《Tensorflow教程》观看地址:http://t.cn/RTuDxFT
最后一个很棒的资源是《 Deep Learning With Tensorflow》,其实里面Tensorflow的介绍得并不多,更多的是用简明的方式把Deep Learning里重要的知识都给你过了一遍,全长也就一个小时左右,用你可能玩不了一局吃鸡的时间去再次巩固下知识还是不错的呢!
《 Deep Learning With Tensorflow》观看地址:http://t.cn/RTuDcjC
至于keras,它比较简单啦,产品经理童鞋可以学完深度学习基本知识后,直接上手下面这个视频,给大家推荐的是莫烦童鞋的《Keras快速搭建神经网络》,教程视频约两个小时,一部电影的时间就可以把它消灭掉,有没有很开心!
《 Keras快速搭建神经网络》观看地址:http://t.cn/RTuDLKD
一路下来,python我们提到了,数学和算法也说到了,深度学习框架我们也说到了,李杰克你TM该结束这篇文章了吧?
各位童鞋稍安勿躁,真的是最后一点点东西了,我不骗你的......因为我也快把自己写得快崩溃了.....
我们都知道深度学习可能会用到比较大的数据,��而CPU是很难带动大数据的训练的,GPU这个大杀器就不一样了,它会让训练的速度提升很多,所以,我们往往愿意选择GPU来训练模型。
但是,我们小白哪来的GPU啊?
当然我们可以去买,但性能还不错的GPU的价格可是一点都不比我们用的笔记本便宜哟......
但你也不要慌,作为前产品经理的李杰克显然也考虑到了这一点,且听我告诉你解决方案。
世界上有一种神奇的服务叫......不好意思,不是你所想的大宝剑......而是云服务。
我们不想买GPU,但我们可以去租人家的的GPU来用嘛,其中Amazon 的AWS是个不错的选择。
我们需要训练的时候去临时租用它就好了,使用期间一个入门级GPU竞价实例也就是0.2刀每小时,这个性价比自然是棒棒哒!不过最近竞价示例似乎有时候会连不上,这时可以考虑用普通GPU实例,不过价格就需要0.9刀每小时了。
具体怎么使用AWS李杰克不展开讲了,提供一篇说的还算详细的攻略文章《在AWS上配置深度学习主机》给各位童鞋参考,以备大家不时之需。
《在AWS上配置深度学习主机》阅读地址:http://t.cn/RxdOFOb
尾声
我的天呐,终于写完了啦!
讲真,李杰克以前属于那种学习知识过后很少会再把知识写出来的人,因为从功利的角度来说,去重复已经掌握的东西对自己并没有太大帮助。
同时,李杰克也是一个有点处女座性格的人,总是希望能够呈现给大家尽可能有价值有意思的东西,所以经常觉得自己没写好,然后重新写,写的过程也会比较纠结和费时。
但是,李杰克还是愿意把这件事情坚持下去,因为李杰克觉得为大家写东西是有意义的,跟大家交流探讨是有意思的,与大家一起共同进步是开心的。
如果这篇文章能够对大家有那么一些些帮助,李杰克会觉得很有成就感!毕竟我也是耗费了不少心血和时间的东西也有了些反馈,你敢信,我给部分文字标粗标色就花了一个多小时(生无所恋脸).....希望大家多多支持!
额.....突然想起我好像把最重要的事情忘了:各位美貌与智慧并重、英雄与狭义的化身的童鞋们,如果你觉得本文对你还有些许帮助的话,欢迎通过后文的二维码关注李杰克的公众号“小白AI之路(AI-Learning)”(请再次脑补我无比大写的谄媚脸)!
如果童鞋你想要获得李杰克精心收集和整理并验证有用的以上各种学习资料,请转发此文章到朋友圈后再截图发送到公众号“小白AI之路”后台,李杰克会在一天之内给到你提供下载地址和密码。
AI是Artificial Intelligentce的缩写,中文是大家广知的“人工智能”。 AI可以理解为让机器具备类似人的智能,从而代替人类去完成某些工作和任务。
很多小伙伴对AI的认知可能来自于《西部世界》、《AI》、《超能陆战队》、《机器人总动员》、《超能查派》等影视作品,这些作品中的AI都可以定义为“强人工智能”,因为他们能够像人类一样去思考和推理,且具备知觉和自我意识。
但强人工智能在现实中的发展基本处于停滞状态,目前AI的研究和应用基本都集中在“弱人工智能”领域,弱人工智能可以理解为机器看起来像是智能的,但并不会具备知觉和意识。
弱人工智能领域的AI实现,可��以分为两种方式:
一种是通过对相关规则进行编程,让机器能够按照程序中存在的逻辑处理特定任务,从结果来上看机器是智能的;
另一种是我们不给机器规则,取而代之,我们喂给机器大量的针对某一任务的数据,让机器自己去学习,继而挖掘出规律,从而具备完成某一任务的智能,这种方式,也就是我们今天的主角——机器学习。
不好理解?举一个简单的例子,如果我们需要让机器具备识别狗的智能:
第一种方式意味着,我们需要将狗的特征(毛茸茸、四条腿、有尾巴...)告诉机器,机器将满足这些规则的东西识别为狗;
第二种方式意味着,我们完全不告诉机器狗有什么特征,但我们喂给机器10万张狗的图片,机器就会自个儿从已有的图片中学习到狗的特征,从而具备识别狗的智能。
此狗以一根火腿肠的身价友情出境...
AI可以说是跟机器学习紧密联系在一起,那我们在来说下我们今天的主角——机器学习。
首先,机器学习从模型层次结构的角度可以分为浅层学习和深度学习,简单介绍下两者:
1. 浅层学习**(Shallow Learning)**
浅层学习与深度学习(Deep Learning)相对,它的模型层次较浅,通常没有隐藏层或只有一层隐藏层。
浅层学习常见的算法有线性回归、逻辑回归、随机森林、SVM、K-means、RBM、AutoEncoder、PCA、SOM等等。
隐藏层什么鬼?这些算法什么鬼?没关系,能记上一两个名字很好,暂时记不住也没关系,我们以后会捡重要的来讲。
浅层学习算法可以做一些预测��、分类、聚类、降低数据维度、压缩数据和商品推荐系统等工作。
2. 深度学习**(Deep Learning)**
深度学习的“深”是因为它通常会有较多的隐藏层,正是因为有那么多隐藏层存在,深度学习网络才拥有表达更复杂函数的能力,也才能够识别更复杂的特征,继而完成更复杂更amazing的任务。
令很多童鞋惊叹“AI无所不能,马上就要改变世界、取代人类”的领域,基本都跟深度学习有关系。
目前深度学习的研究和应用,主要集中在CNN和**RNN;**跟着我狠狠地把这些名词记下来(至少缩写要记下来哈),他们会成为后续文章介绍的重点。
CNN为Convolutional Neural Networks的缩写,也就是卷积神经网络,目前是计算机视觉、图像分类领域最主要的算法,当然也有人将它应用于自然语言处理领域。
接下来举些CNN应用场景的例子,让大家有个较直观的印象:
1)前两年大火的Prisma可以将机器学习名画的风格并迁移到新的图片上,比如这张白发女咖啡杯图:
2)深受妹纸喜爱各种美颜相机的滤镜,也是会用到人脸检测,用上之后感觉自己萌萌哒,额...这个好像是个可爱的男孩子...
3)交通监控视频识别来往车辆的车型,目前有些公司的产品还可以识别车牌号:
4) 商场监控视频能够识别人脸,顺便还能根据已有数据判断这个人是否以前来过商场:
5)当下最火的无人车中,无人车需要用计算视觉去观察和理解这个世界:
RNN为Recurrent Neural NetWorks的缩写,��也就是递归神经网络,基于RNN还衍生出了LSTM(Long-Short-Term-Memerory)和GRU(Gated Recurrent Unit)等一系列算法,这些算法拥有记住过去的能力,所以可以用来处理一些有时间序列属性的数据,在处理语言、文字等方面有独到的优势。
RNN及其衍生算法可用于语音识别、机器翻译、合成音乐等等,我们仍然来简单举几个的例子:
1) 以Siri、小娜、小冰、小度为代表的对话机器人,调戏Siri让她bbox和唱歌讲段子并不能充分体现你的无聊,下次你可以试试让Siri和小娜互相对话:
2) 以谷歌翻译为代表的机器翻译,不管是文字翻译还是语音翻译,都把可以把人类翻译虐成渣渣:
3) 老罗在锤子发布会上大吹特吹的能够以极高准确率和极快速度将语音转化为文字的讯****飞输入法:
4)有粉丝等不及乔治·马丁老爷子写**《冰与火之歌》第六部,就自己用LSTM**算法学习了《冰与火之歌》的前五部后续写了第六部,据说AI这部作品中还揭示了前几部中埋了很久的悬念:
3
说AI简单,因为AI本质上都是一个函数
如果你坚持看到这里,你对AI的理解和认知大概率已经击败了你朋友圈里50%经常分享AI将改变世界取代人类的好友们。
此刻你已经可以在聊天中用对方大概率听不懂的CNN、RNN、LSTM等一众名词来彰显你的逼格了。
但是,作为稳重踏实、拥有内涵、崇尚科学的新时代好青年的我们来说,这还远远不够,我们总是希望能够不动声色、低调内敛、用对方看似都懂实则不懂的东西去装更高规格的逼。
接下来,请跟我学习下正确的装的�方式:XX,你知道么?其实,AI很简单,因为AI本质上都是一个函数。
是这样的,XX,这其实很好理解,AI其实就是我们喂给机器目前已有的数据,机器就会从这些数据里去找出一个最能满足(此处用“拟合”或可提升逼格)这些数据的函数,当有新的数据需要预测的时候,机器就可以通过这个函数去预测出这个新数据对应的结果是什么。
说完之后,请微微抬头看向远方,感慨一下:万物自有其道,人世间多少复杂的东西到末了还是要归于纯粹啊。
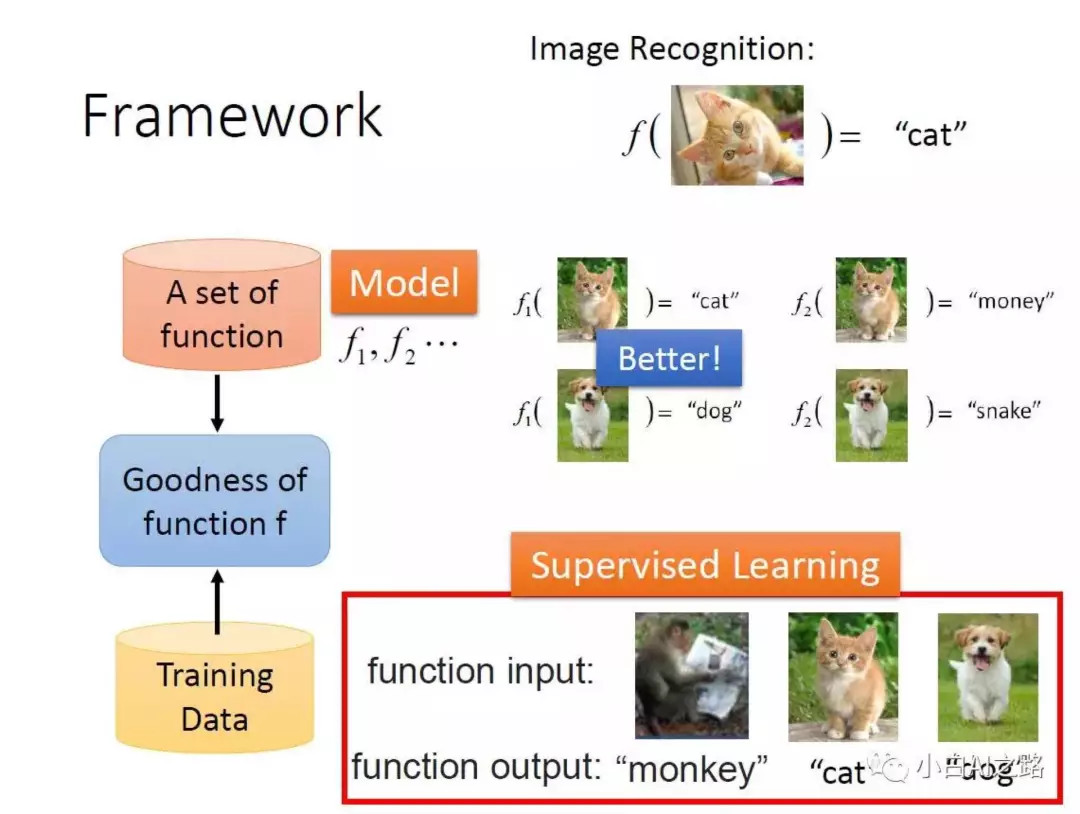
对于一个具备某种智能的模型而言,一般具备以下要素:数据+算法+模型,请狠狠地记住这三个词;记住了这三个词,AI的本质你也就搞清楚了。
这个时候我们再把高冷的猫也请出来,我们来用一个能够区分猫和狗图片的分类器模型来帮助理解这个问题:
“数据”就是我们需要准备大量标注过是“猫”还是“狗”的图片,为什么要强调大量,因为只有数据量足够大,模型才能够学习到足够多且准确的区分猫和狗的特征,才能在区分猫狗这个任务上,表现出足够高的准确性;当然数据量不大的情况下,我们也可以训练模型,不过在新数据集上预测出来的结果往往就会差很多。
“算法”指的是构建模型时我们打算用浅层的网络还是深层的,如果是深层的话我们要用多少层,每层有多少神经元、功能是什么等等,也就是网络架构的设计。相当于我们确定了我们的预测函数应该大致结构是什么样的,我们用Y=f(W,X,b)来表示这一函数,X是已有的用来训练的数据(猫和狗的图片),Y是已有的图片数据的标签(该图片是猫还是狗),聪明的你会问:W和b呢?问得好,**函数里的W(权重)和b(偏差)我们还不知道,这两个参数是需要机器学习后自己找出来的,**找的过程也就是模型训练的过程。
“模型”指的我们把数据带入到算法中进行训练,机器就会去不断地学习,当机器找到最优W(权重)和b(偏差)后,我们就说这个模型是train成功了,这个时候我们的函数Y=f(W,X,b)就完全确定下来了。然后我们就可以在已有的数据集外给模型一张新的猫或狗的图片,那模型就能通过函数Y=f(W,X,b)算出来这张图的标签究竟是猫还是狗,这也就是所谓的模型的预测功能。
到这里,你应该已经能够理解AI的本质了。我们再简单总结下:不管是最简单的线性回归模型、还是较复杂的拥有几十个甚至上百个隐藏层的深度神经网络模型,本质都是寻找一个能够良好拟合目前已有数据的函数Y=f(W,X,b),并且我们希望这个函数在新的未知数据上也能够表现良好。